活動報告
PILOT
「深層学習を用いた中国漢代木簡画像からの文字領域検出」 吉田壮
中国漢代木簡にみられる行政文書(漢代簡牘文書)の字体を解析する手法の構築を目標としています。漢代簡牘文書の「書きぶり」に注目し、感覚的に捉えられてきた字体の崩し方を一定度定量化して客観的判定の基礎を構築することが目的です。
今年度はその初期検討として、木簡1件ごとにデジタル化した画像から文字を1つずつ切り出す、文字領域検出技術を開発しました。近年、文字の切り出しのため、物体検出の適用に注目が集まっています。物体検出は画像の複数種類の物体の位置を特定してクラス(物体名を指す)分類することを可能にする、実用的で応用範囲が広い技術です。畳み込みニューラルネットワークを代表とする深層学習の発展に伴い、一部の分野では人間よりも識別能力が高いという報告もあります。しかし、文字領域検出の問題を考えた際、漢字は部首など複数の構成要素で成り立つため、1つの文字の区切りが明確でない場合が多く、これが大きな課題となります。そこで我々は、文字と文字の間に必ず隙間を設ける、中国漢代木簡にみられる書き方の特性を活かすことで、高精度に文字領域を検出することを可能としました。
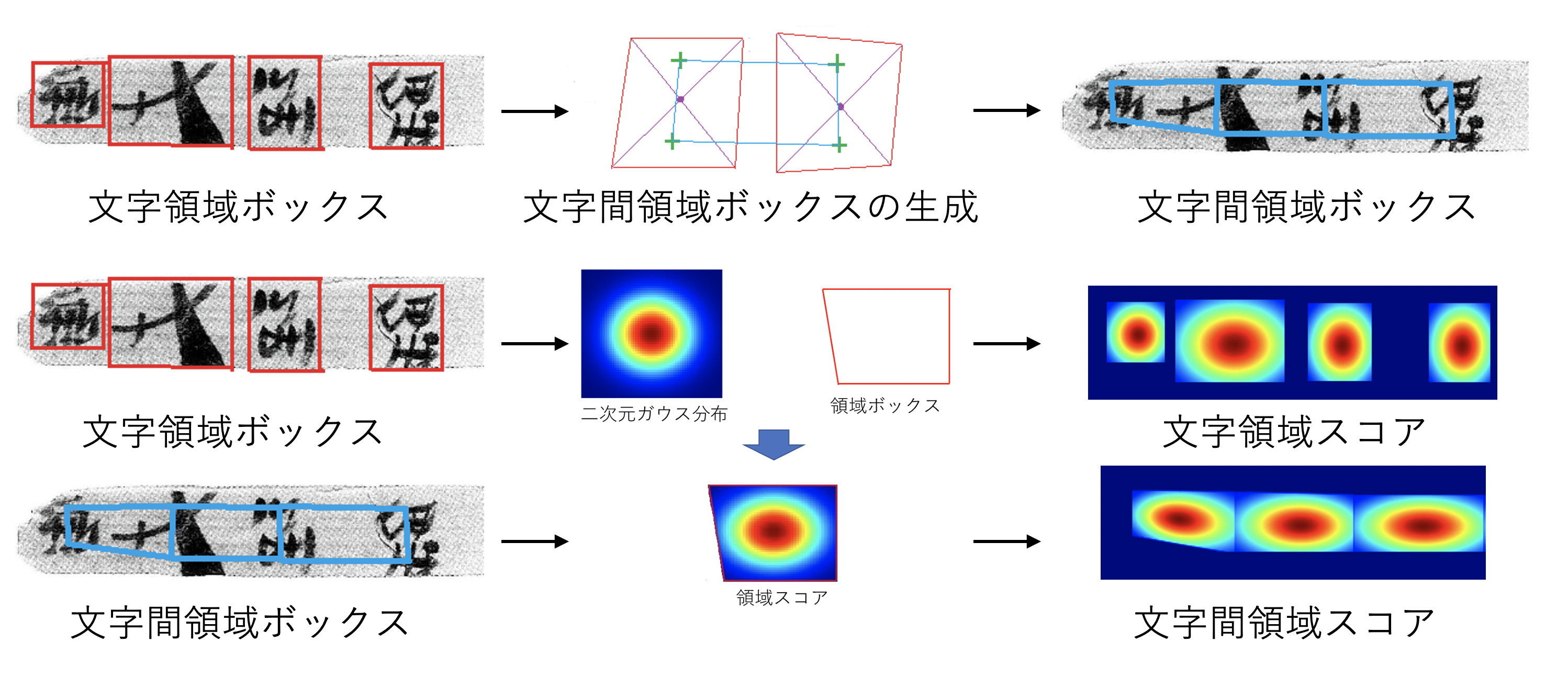
具体的に、従来のように文字位置を特定するのみでなく、文字間の領域を同時に特定することで、1文字の区別を容易にしました。U-Netと呼ばれる文字の微細な特徴と位置関係を学習可能な深層学習に基づいて、文字領域と文字間領域を同時に特定することが可能なモデルです(図1参照)。
【図1】
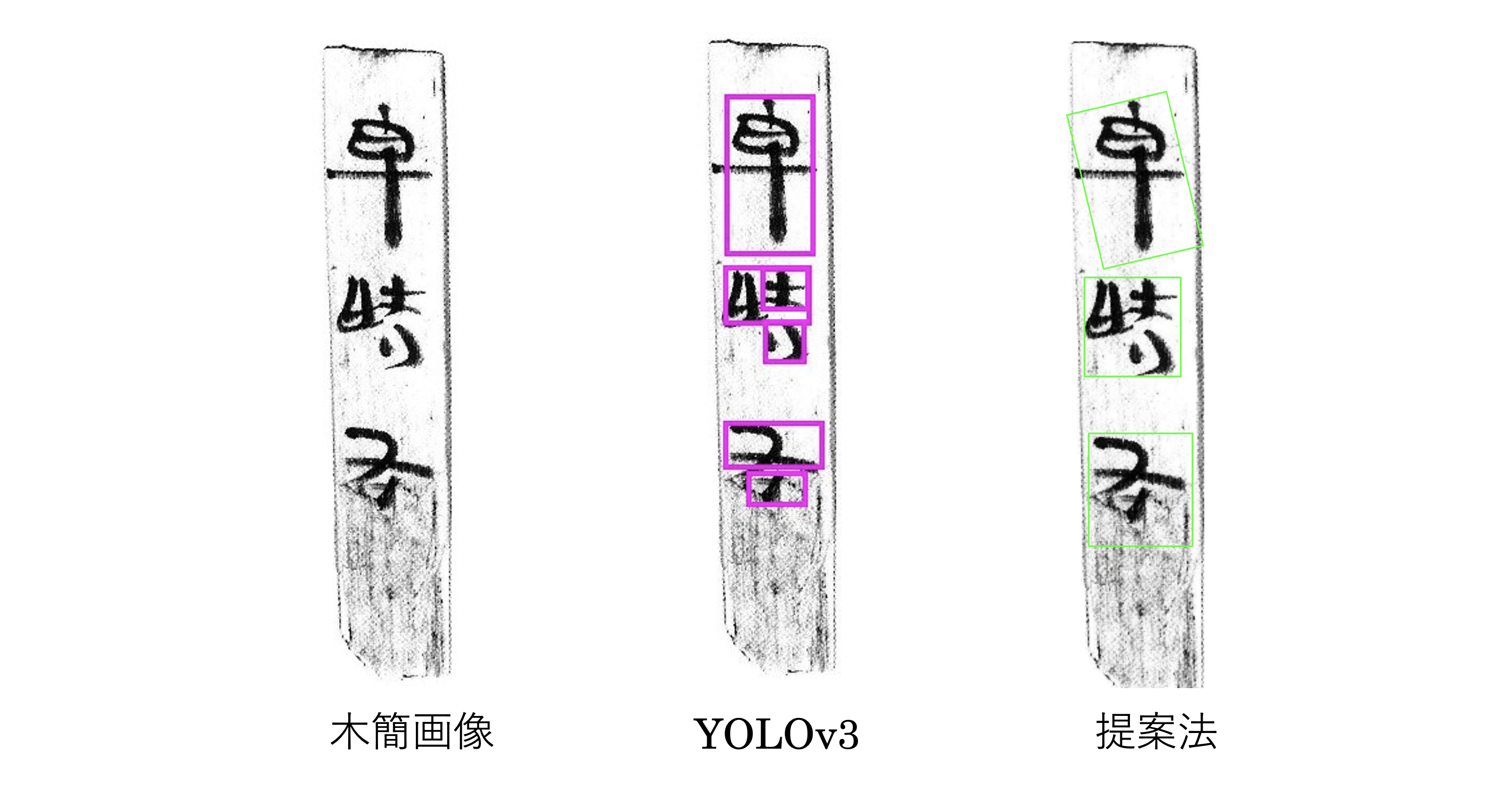
実際に、中国漢代木簡「居延漢簡」に提案法を適用した結果を示します(図2参照)。提案法の有効性を示すため、高精度で知られる物体検出法(YOLOv3)を比較に示します。図から比較法と比べて文字の領域を正しく特定できていることが分かります。今後は、提案法を用いて抽出された文字の字体を解析する技術を開発する予定です。
【図2】